Filtrer ses logs à coups de GREP (étape 1)
Dans cet article, nous allons partir de logs bruts et allons uniquement récupérer tout ce qui concerne Google (crawl et visites). En effet, lorsque nous allons traiter les logs par la suite, nous préférerons traiter des fichiers les plus légers possibles afin de ne pas trop ralentir les temps de traitement.
Les étapes décrites ci-dessous seront volontairement détaillées et découpées afin de bien comprendre ce que nous souhaitons extraire.
Tout d’abord, nous allons décompresser les logs. Si ils sont en .gz, placez vos logs dans un dossier, et tapez alors la commande suivante : [shell]
gunzip *.log.gz
[/shell]
Ceci aura pour but de dézipper tous les fichiers terminant en .gz et de les supprimer.
Extraire tout ce qui concerne Google
Afin de travailler sur un fichier allégé, nous allons uniquement extraire toutes les lignes qui contiennent « google », et écrire le résultat dans un seul fichier.
Pour cela nous utilisons la commande suivante :
[shell]
grep google *.log > logs-google.txt
[/shell]
Cette commande va extraire (grep) toutes les lignes contenant google se trouvant dans tous les fichiers se terminant par .log (à personnaliser en fonction des besoins). Le résultat sera inscrit (>) dans un fichier s’appelant logs-google.txt.
Jetez un oeil sur la taille du nouveau fichier : il ne pèse pas lourd par rapport à tous les logs que vous venez de télécharger sur votre serveur. Je compte quelques secondes sur mon PC pour un fichier log de 500 Mo.
Maintenant que nous avons uniquement les lignes contenant Google, nous allons différencier le crawl, visites, et autres.
Extraire des logs le crawl de Google
Avant d’extraire les lignes de crawl de Google, il faut se poser la question de comment reconnaître le crawl de Google ? Il s’agit de lignes, dont l’IP va commencer par 66.249 et dont le user-agent va contenir Googlebot.
Attention ici, car :
- Il existe d’autres crawlers de Google n’ayant pas cette IP : crawler Adsense par exemple
- Il existe des crawlers ayant le même user-agent que Google mais qui n’appartiennent pas à Google (pirates usurpant le user-agent de Google).
Il est donc bien important d’extraire à la fois les lignes commençant par l’IP de Google et possédant le bon user-agent (c’est finalement une sécurité).
Regardons nos logs de plus près.
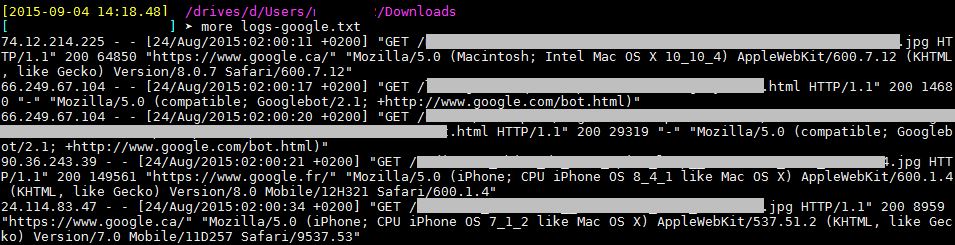
La première lignes est une visite, puisqu’elle possède un referer (https://www.google.ca).
La deuxième ligne est un crawl de Googlebot, puisque l’IP commence pas 66.249 et que le user-agent est bien celui de Googlebot.
Nous allons dans un premier temps extraire toutes les lignes commençant par 66.249 puisque l’IP est le premier champs de mes logs. Puisque j’ajoute la notion de « ligne qui commence », je vais utiliser une expression régulière en ajoutant l’option -P de grep :
[shell]
grep -P « ^66.249. » logs-google.txt > logs-google-ip.txt
[/shell]
J’ai maintenant dans mon fichier logs-google-ip.txt les lignes de logs correspondant au crawl de Google. Attention, car j’ai tout le crawl de Google. Il faut maintenant soit filtrer sur le bot que l’on souhaite suivre, soit exclure les bots que l’on ne souhaite pas suivre.
Si l’on souhaite extraire un bot en particulier, nous allons taper :
[shell]
grep « nom_du_bot » logs-google-ip.txt > sortie.txt
[/shell]
SI l’on souhaite exclure un bot du fichier en particulier, nous allons taper :
[shell]
grep -v « nom_du_bot » logs-google-ip.txt > sortie.txt
[/shell]. Ceci créera un fichier sortie.txt contenant toutes les lignes du précédent sauf les lignes contenant le bot à exclure.
Voir la liste des robots de Google existants
Extraire des logs les visites de Google
Les visites elles, sont reconnaissables car elles possèdent un champ referer, contenant google.tld. C’est là où grep connaît ses limites : sa seule utilisation se révèle difficile pour extraire les visites. En effet, il faut faire un grep sur la colonne du referer (ou alors être très bon en expressions régulières). Je ferai un post sur l’utilisation de cut, sed, awk plus tard.
Si nous utilisons seulement grep, nous pouvons au choix :
- Exclure de nos logs google tout ce qui n’est pas ^66.249 (mais il resta les ips pirates)
- Exclure tout ce qui n’a pas de user-agent
- Extraire les referers correspondant à des visites
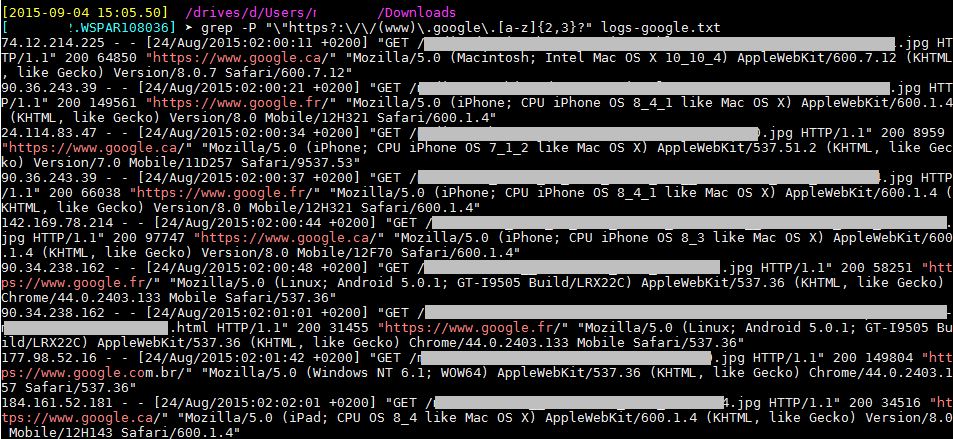
Tentons le coups de récupérer les referers visites seo. J’extrait ce qui commence par « http(s)://(www).google.tld* :
[shell]
grep -P « \ »https?:\/\/(www)\.google\.[a-z]{2,3}? » logs-google.txt > logs-google-visites.txt
[/shell]
Voici ce que l’on obtient :

Vous trouverez dans ce nouveau fichier toutes les visites provenant de Google, mais également les visites images, css, js. Elles sont à supprimer car : lors d’une visite SEO vers une page de votre site, des ressources téléchargées en même temps que la page se verront obtenir un referer. A vos grep -v !



Laisser un commentaire