Ce crawl va récupérer une liste d’URL d’un site en récupérant :
- Title
- H1
- Temps de réponse
- Liens internes entrants / sortants
- Profondeur
- Status code (code réponse
Création de la base
Je crée tout d’abord une base vide, qui sera ma base de crawl. Je l’appelle « mnogo_recettesdemarie_url ». Je peux la créer directement via l’interface graphique de PHP My Admin.
Création d’un fichier de configuration
Dans cet exemple, je vais crawler mon blog de cuisine : www.recettesdemarie.fr.
Je prépare un fichier de configuration pour Mnogosearch, avec le minimum d’informations (pour cet exemple), afin de lancer un crawl. Ce fichier, que j’appelle recettesdemarie-url.conf je l’ai placé dans un dossier appelé /mnogosearch_conf/, dossier situé dans /usr/local/ où se trouve le dossier de /mnogosearch/.
Attention, quelques modifications sont nécessaires par rapport à un fichier de configuration pour un crawl de site « classique ». Il faut en effet définir une profondeur maximum à 1 (MaxHops 1) et ne pas suivre les liens (FollowLinks no). On fait bien sur attention d’être dans la bonne base de données.
Dans ce fichier de configuration, je renseigne, dans l’odre :
- Connexion à la base de données (bien renseigner la table)
- Un user-agent personnalisé (permet de simuler Googlebog sur la base du user-agent, mais pas de l’ip)
- Exclusion des patterns de medis (images…)
- Suivi des règles du robots.txt
- Sections que l’on souhaite récupérer (ici title, temps de réponse, h1)
- La manière dont on souhaite suivre et récupérer l’information des liens (ici tous les liens seront collectés, même lorsqu’ils sont en doublons)
- Vitesse du crawl
- Le domaine à crawler
###CHEMIN DACCESS A LA BDD DBAddr mysql://login:motdepasse@localhost/mnogo_recettesdemarie_url/?DBMode=blob ###TOUTE LA GESTION DES ENTETES HTTP SE FAIT VIA LA DIRECTIVE HTTPHeader HTTPHeader "User-Agent: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html" ###AJOUTER OU EXCLURE DES PATTERNS Disallow *.b *.sh *.md5 *.rpm Disallow *.arj *.tar *.zip *.tgz *.gz *.z *.bz2 Disallow *.lha *.lzh *.rar *.zoo *.ha *.tar.Z Disallow *.gif *.jpg *.jpeg *.bmp *.tiff *.tif *.xpm *.xbm *.pcx Disallow *.vdo *.mpeg *.mpe *.mpg *.avi *.movie *.mov *.wmv Disallow *.mid *.mp3 *.rm *.ram *.wav *.aiff *.ra Disallow *.vrml *.wrl *.png *.ico *.psd *.dat Disallow *.exe *.com *.cab *.dll *.bin *.class *.ex_ Disallow *.tex *.texi *.xls *.doc *.texinfo Disallow *.rtf *.cdf *.ps Disallow *.ai *.eps *.ppt *.hqx Disallow *.cpt *.bms *.oda *.tcl Disallow *.o *.a *.la *.so Disallow *.pat *.pm *.m4 *.am *.css Disallow *.map *.aif *.sit *.sea Disallow *.m3u *.qt ###COMPORTEMENT ROBOTS META OU SERVEUR. LES URLS BLOQUEES SONT STOCKEES EN BASE AVEC LE STATUT PERSONNALISE 199 Robots yes ###RECUPERATION DE SEGMENTS DANS LE SOURCE HTML Section title 1 256 Section ResponseTime 2 32 Section h1 3 256 "(<h1[^<]*>)?([^<]*?)</h1>" "$2" ###SUIVI DES LIENS FollowLinks no CollectLinks yes ###VITESSE DU CRAWL EN SECONDES ET PROFONDEUR MAXHPS MaxHops 1 CrawlDelay 2 CrawlerThreads 6 ###CE QUE L'ON CRAWLE Server http://www.recettesdemarie.fr/
Préparation des bases
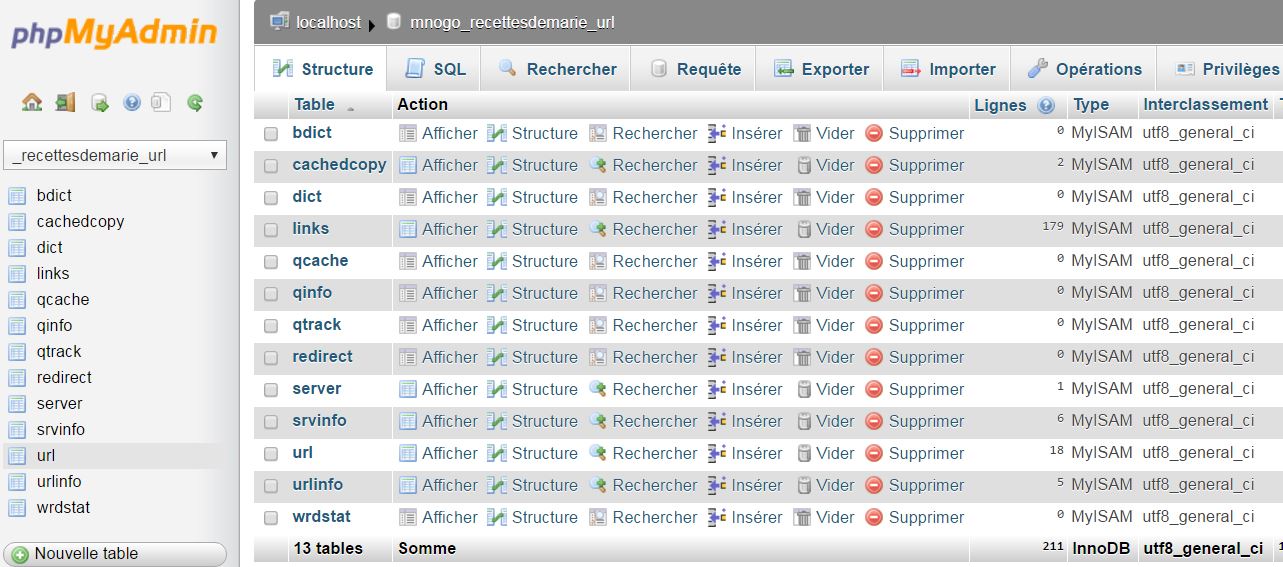
Ensuite, comme pour un crawl classique, je dois créée les tables (vides) de ma base. Ces tables seront remplies par le crawler. Afin de créer les tables, je fais la commande suivante :
mnogosearch/bin/indexer -d mnogosearch_conf/recettesdemarie-url.conf --create.
Voici l’écran que j’obtiens :

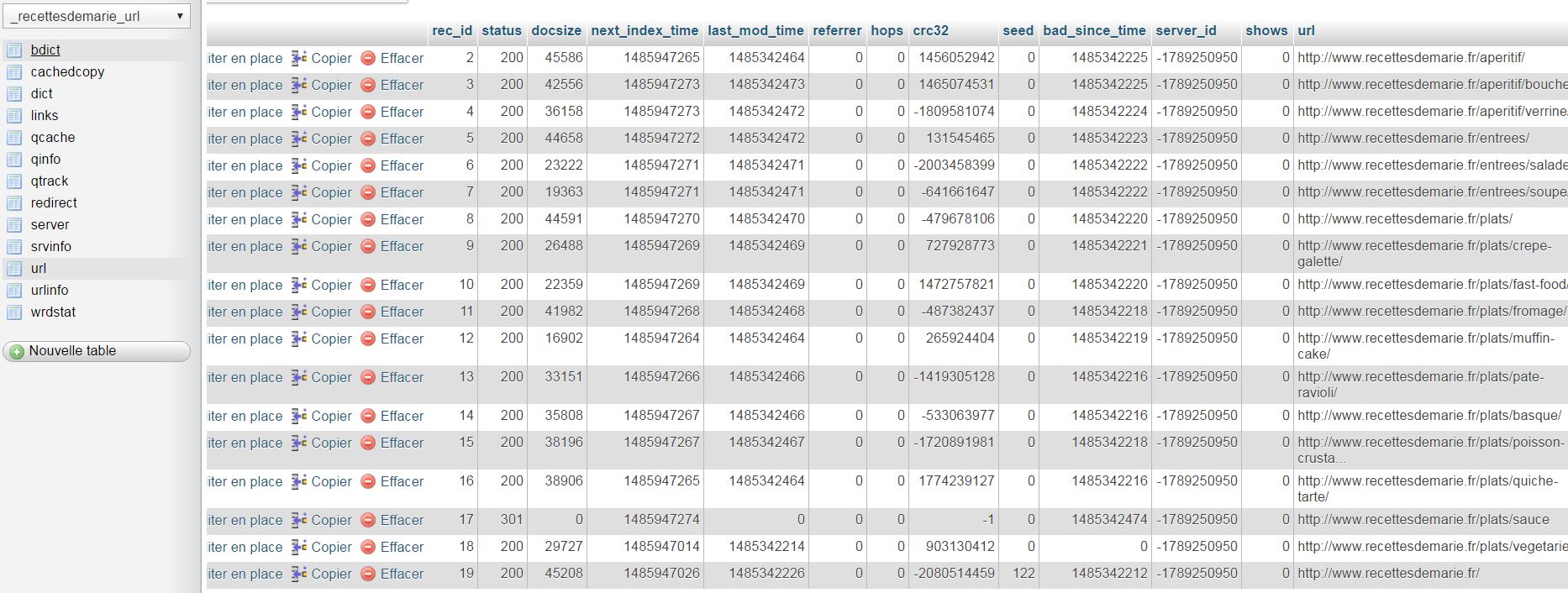
Et voici ce que j’obtiens dans mes bases SQL :
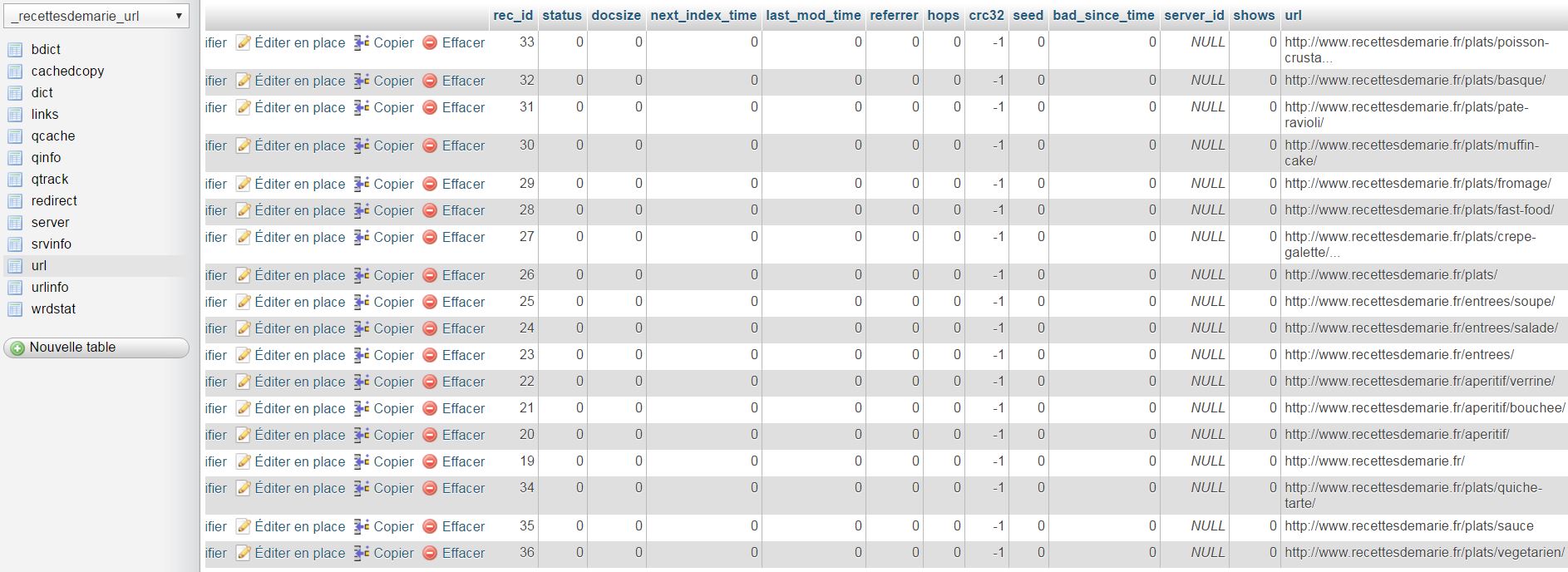
Etape supplémentaire par rapport à un crawl classique, je remplis le champs « url » de la table « url ». Je préfère passer par l’invit de commande car l’interface de PHP My Admin risque de ne pas supporter de trop gros fichiers.
Attention au fichier que vous uploadez : il se peut qu’il génère des retours à la ligne ou des caractères spéciaux qui seront insérés en base de données et créeront des 404. On peut par exemple dans Notepad++ remplacer les \r\n par des \n.
Pour cela :
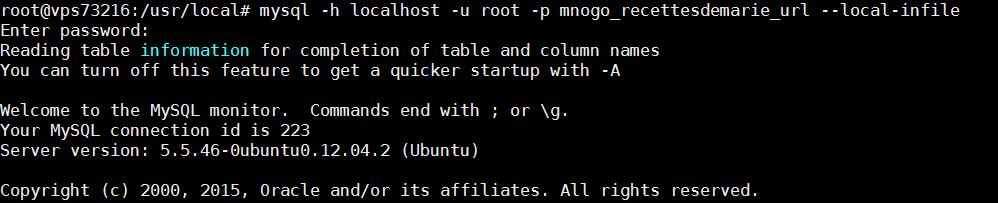
- Je me connecte à SQL (j’autorise l’upload de fichier via la commande LOAD DATA INFILE):
mysql -h localhost -u root -p mnogo_recettesdemarie_url --local-infile
- Je me place dans la bonne base de données
use mnogo_recettesdemarie_url
- J’upload mes urls
LOAD DATA LOCAL INFILE 'mnogosearch_conf/url.txt' INTO TABLE url(url);
Voici ce que j’obtiens en lignes de commande :
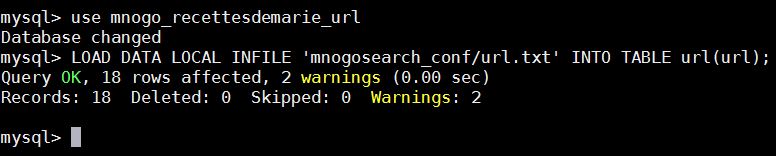
Et voici ce que j’obtiens du côté de PHP My Admin :
Lancement du crawl
Il est l’heure de lancer le crawl !
Je quitte l’interface de mysql et je lance la commande suivante :
mnogosearch/bin/indexer -a -d mnogosearch_conf/recettesdemarie-url.conf
J’obtiens l’écran suivant :
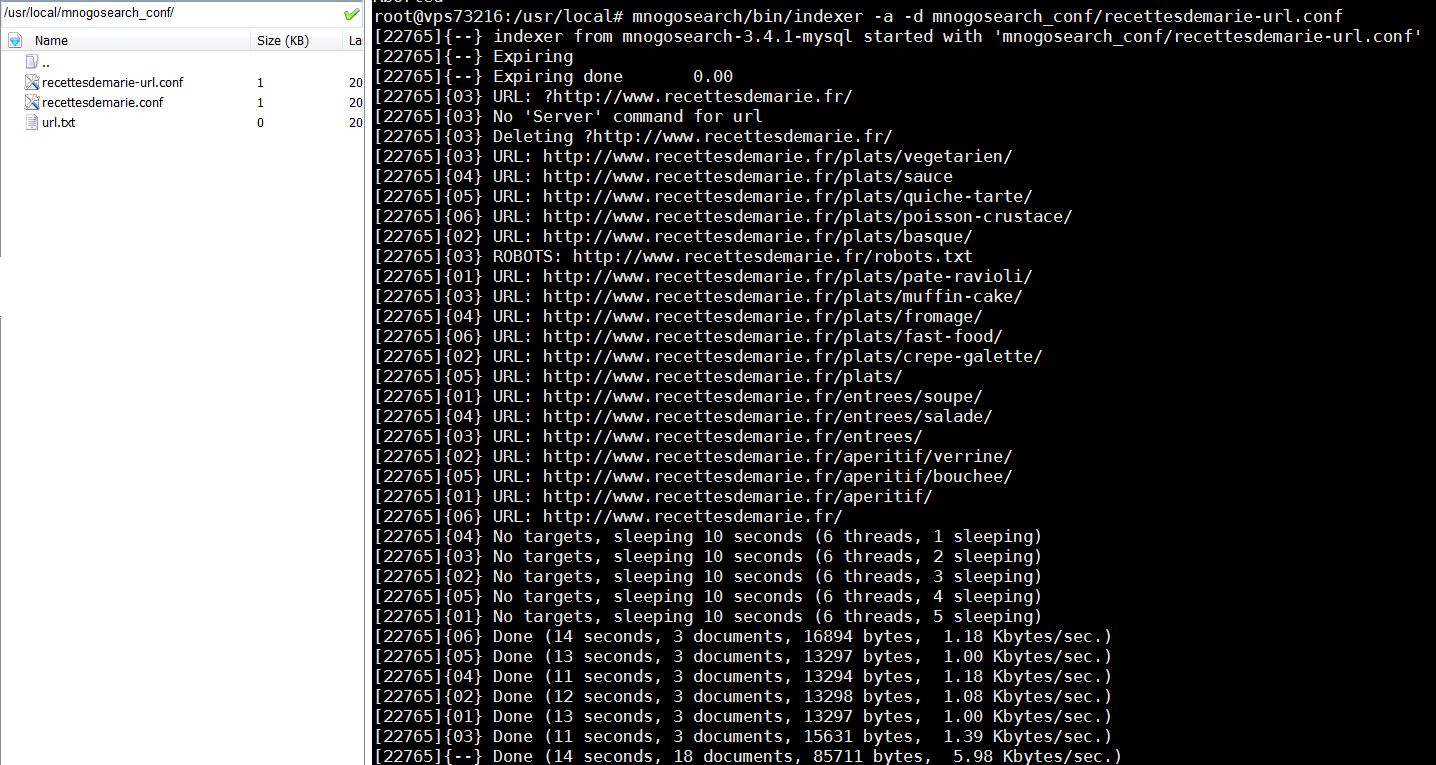
Et dans ma base de données, mes tables se remplissent avec uniquement les données des URL voulues.