Pourquoi cet article ?
Suite à l’article de Google sur son blog pour webmasters, j’ai souhaité à mon tour publier, car j’ai vu passer plusieurs articles sur le sujet du budget de crawl qui me semblent incomplets voire pas tout à fait en accord comparé à ce que j’observe côté logs Google. Je souhaite dans cet article expliquer le budget de crawl différemment, mais surtout illustrer par des comportements de Google la raison pour laquelle il est important d’y prêter attention.
Comment fonctionne Google ?
Tout d’abord, il est important de rappeler (schematiquement) la manière dont fonctionne Google :
- Google Bot crawle le web : Google parcourt toutes les pages qu’il trouve sur le web, navigue de liens en liens et crawle le contenu des pages.
- Google insère les pages dans son index : en fonction des critères de l’algorithme de Google ou de directives données, celui-ci choisit ou non d’indexer les pages.
- Google affiche les résultats : Google présente les résultats qui lui semblent le plus pertinent sur une requête donnée. Le classement de ces résultats dépend de l’algorithme de Google qui prend en compte plusieurs facteurs en compte comme le contenu de la page, la structure, la popularité…
A partir de là, on peut se dire que le « job » est terminé : mon site est indexé, et il remontera mieux ou moins bien dans le futur grâce aux optimisations que je fais, on-site ou off-site, et que Google prendra en compte lors de ses prochains passages. C’est sur ce point que je souhaite revenir, car le crawl doit se monitorer et se maintenir tout au long de la vie d’un site. En effet, une page indexée n’est pas un indicateur fiable de bonne santé d’un site : Google possède beaucoup de pages de mauvaises qualités dans son index, et ne remonteront pas dans les résultats (on retrouve même des pages bloquées dans le robots.txt).
Qu’est-ce que le budget de crawl ?
Google possède une puissance de crawl folle, puisqu’il arrive à explorer des milliards de contenus, en un temps record. Cette puissance a un coût et prend du temps : c’est la raison pour laquelle Google ne crawle pas un site dans sa globalité en un jour (même des sites à faible volume de pages) : il va mettre des jours, des semaines, des mois voire… des années !
L’objectif SEO est de faire en sorte que non seulement Google crawle l’ensemble des pages en un minimum de temps, mais qu’il se focalise sur les pages importantes du site : qui possèdent du contenu, qui génèrent du business…
Quels sont les critères pour qu’une page génère de la visite ?
C’est la question, souvent absente des articles liés au sujet, et c’est pourtant la principale raison pour laquelle le budget de crawl est important : pour qu’une page génère de la visite, elle n’a pas simplement besoin d’être indexée, elle a également besoin d’être crawlée !
L’indexation et le crawl sont deux prérequis pour le positionnement d’une page.
Deux choses à savoir :
Premièrement, une page qui n’est pas crawlée ne génère pas de visite. Plus précisément, une page qui n’a pas été crawlée depuis un laps de temps important a peu voire aucune chance de générer du trafic. Ce laps de temps n’est pas la même en fonction des sites (et de leur volumétrie) et des typologies de pages : cela peut aller d’un mois à plus.
Deuxièmement, une page crawlée ne rapportera pas forcément du trafic : c’est là que l’algorithme de Google va intervenir pour classer les résultats. Par contre, une page de qualité très crawlée a plus de chances de bien se positionner.
Lors d’une analyse de logs, on regardera en premier lieu (en plus des erreurs rencontrées) :
- Les pages qui ne sont pas crawlées : sont-elles des pages qui ont une change de générer du trafic et faut-il leur ramener du crawl ?
- Les pages crawlées génèrent-elles du trafic ? Google dépense t-il inutilement de l’énergie sur des pages qui ne sont pas destinées à se positionner ou s’agit-il de facteurs on-site / off-site ?
J’ai déjà observé 50% à 90% de crawl inutile sur certains sites ou templates de sites.
Une fois l’étape du crawl utile / inutile, on va se concentrer sur le crawl des pages qui génèrent du trafic. C’est là que ça devient intéressant, car c’est très lié à la typologie de site et de ses templates.
Exemple d’un site à contenus « froids/tièdes » :
Dans cet exemple, on peut dire que :
- Chaque jour, 50% qui génèrent du trafic ont été crawlées dans les 15 jours.
- Chaque jour, 30% des pages qui génèrent du trafic on été crawlées le jour ou la veille.
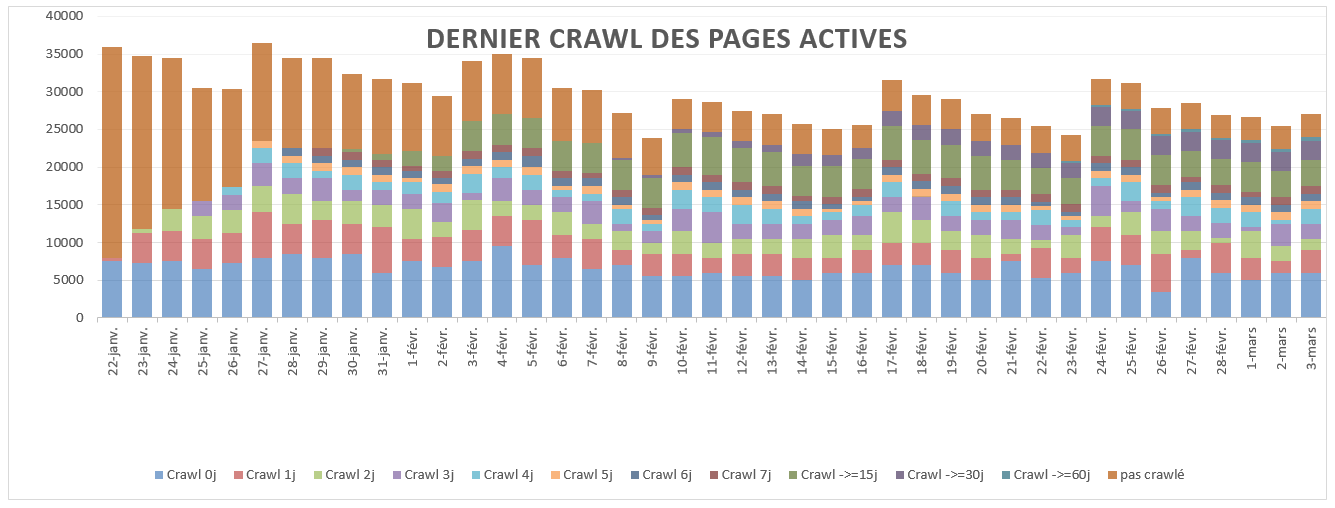
Exemple d’un site à contenus « chauds » :
Dans cet exemple, on peut dire que :
- Chaque jour, +95% des pages qui génèrent du trafic ont été crawlées le jour même.
Il s’agit ici de la typologie de crawl des pages qui génèrent du trafic d’un site à contenus « chauds » : ce sont des pages dont le contenu est souvent mis à jour, où qui viennent d’être mis en ligne.C’est le genre de comportement des pages actives des articles d’un site de news (ici, cas de la rubrique news « sport » d’un site TV.
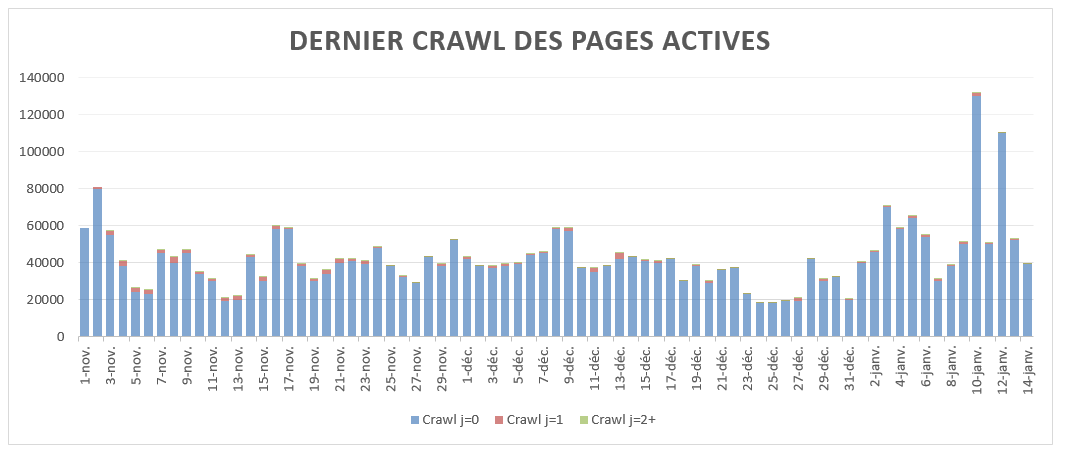
Je ne mets que deux graphes ici, mais on pourrait aller plus loin dans l’analyse de logs :
- Est-ce que ce sont toujours les mêmes pages qui génèrent du trafic ou des nouvelles ?
- En combien de temps Google crawle t-il mes pages qui génèrent du trafic ?
- etc
Sur les sites à forte volumétrie ou contenus « froids » :
Sur un gros site (centaines de milliers, millions de pages), on observera souvent qu’une page peut générer de la visite même si elle a été crawlée il y a plus d’un mois :
- Ce trafic correspond généralement à de la long tail : la page peut se positionner au sein d’une faible concurrence, et Google n’a pas besoin de la crawler régulièrement.
Les requêtes « top tail :
- Tout comme pour les contenus « chauds », les pages qui génèrent du trafic sur des mots clés « top tail » (page d’accueil, pages de nav), on besoin d’un crawl plus élevé que les autres pour être légitimes aux yeux de Google. Etant mises en avant dans l’arborescence, le crawl est naturellement plus important que sur les pages internes.
Au final, comment l’optimise t-on ?
Je ne vais pas m’étendre sur le sujet qui a largement été abordé et repris, et vais simplement lister les principaux facteurs :
- Améliorer le temps de réponse de son serveur / chargement des pages
- Augmenter la popularité du site (netlinking)
- Limiter les pages de faible qualité (pages soft 404, pages piratées, pages dupliquées, spider traps, navigation à facettes non optimisées…)
- Mise en cache
- Mise en place de la 304
- Optimisation du robots.txt
- Optimisation de la navigation (profondeur, maillage…)
- …
Un focus tout de même sur le maillage interne : maintenant que l’on connaît l’importance du crawl, il faut non seulement imaginer une stratégie sémantique mais également plus aboutie en terme de structure. En effet, il ne s’agit pas seulement de réduire les niveaux de profondeur, mais de favoriser ou défavoriser les pages en fonction de leur taux de crawl et de leur efficacité. Quelques cas concrets :
- Mailler des pages qui ne génèrent pas de trafic mais qui ne sont pas crawlées afin de leur donnes « une chance » de positionnement ?
- Mettre en avant les pages qui ne génèrent pas de trafic malgré leur bon positionnement ?
- Mailler des marronniers avant les événements pour amener une certaine dynamique de crawl avant le futur positionnement de ces pages
- …